
diff options
| -rw-r--r-- | README.md | 27 | ||||
| -rw-r--r-- | cl.py | 8 | ||||
| -rw-r--r-- | django_clscrap/settings.py | 1 | ||||
| -rw-r--r-- | myapp/templates/index.html | 37 | ||||
| -rw-r--r-- | myapp/views.py | 4 | ||||
| -rw-r--r-- | requirements.txt | 1 | ||||
| -rw-r--r-- | screenshot.jpg | bin | 0 -> 110832 bytes |
{kind=link}
7 files changed, 71 insertions, 7 deletions
diff --git a/README.md b/README.md new file mode 100644 index 0000000..1eb0fff --- /dev/null +++ b/README.md @@ -0,0 +1,27 @@ +# CLscrap + +CLscrap is a craigslist scraper that provides a RESTful API at /api/cl that returns JSON data + + - uses Django and templating + - renders results at /app + +### Installation + +CLscrap depends on following modules + - beautifulsoup4==4.5.3 + - bs4==0.0.1 + - Django==1.10.6 + - requests==2.13.0 + +Install +```sh +$ pip install -r requirements.txt +$ python manage.py migrate +$ python manage.py createsuperuser +$ python manage.py runserver +$ curl http://localhost:8000/api/cl +``` + +### Screenshot + +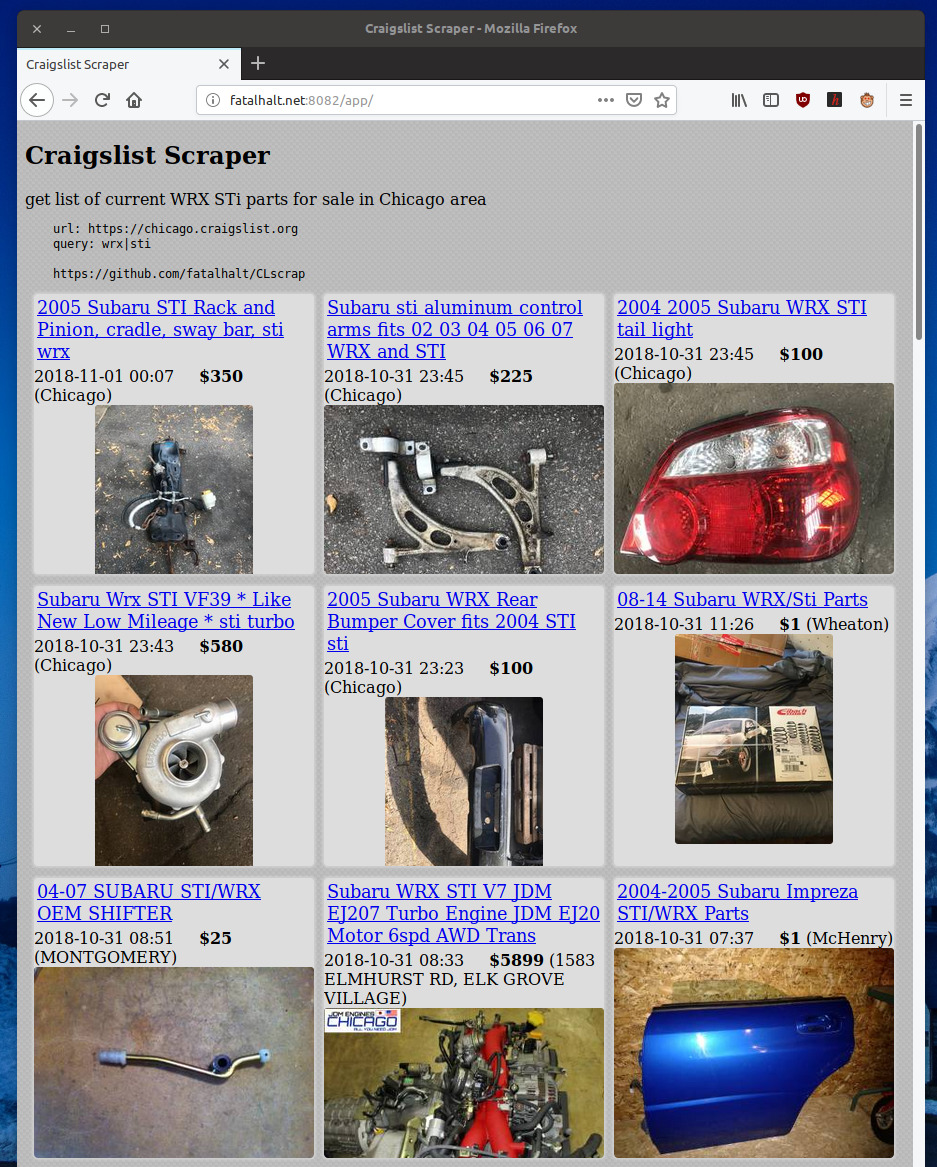 @@ -6,8 +6,8 @@ from bs4 import BeautifulSoup def query_craigslist(baseurl=None, keyword='wrx|sti'): if baseurl is None: - baseurl = 'https://chicago.craigslist.org/' - response = requests.get(baseurl + 'search/pta', params={'query': keyword, 'srchType': 'T'}) + baseurl = 'https://chicago.craigslist.org' + response = requests.get(baseurl + '/search/pta', params={'query': keyword, 'srchType': 'T'}) soup = BeautifulSoup(response.content, "html.parser") results = soup.find_all('li', {'class': 'result-row'}) # at max 120 results per 1 page @@ -27,12 +27,12 @@ def query_craigslist(baseurl=None, keyword='wrx|sti'): except AttributeError: pass # ignore empty fields - return items + return items, baseurl, keyword def main(): parser = argparse.ArgumentParser(description="craigslist WRX and STi parts finder", parents=()) - parser.add_argument("-b", "--baseurl", help='baseurl, e.g. https://chicago.craigslist.org/') + parser.add_argument("-b", "--baseurl", help='baseurl, e.g. https://chicago.craigslist.org') parser.add_argument("-k", "--keyword", default='wrx|sti', help='keyword to search') args, extra_args = parser.parse_known_args() diff --git a/django_clscrap/settings.py b/django_clscrap/settings.py index 39a1021..5c8092f 100644 --- a/django_clscrap/settings.py +++ b/django_clscrap/settings.py @@ -37,7 +37,6 @@ INSTALLED_APPS = [ 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', - 'rest_framework', 'myapp.apps.MyappConfig', ] diff --git a/myapp/templates/index.html b/myapp/templates/index.html new file mode 100644 index 0000000..1a1f618 --- /dev/null +++ b/myapp/templates/index.html @@ -0,0 +1,37 @@ +<!DOCTYPE html> +<html lang="en"> +<head> + <meta charset="UTF-8"> + <title>Craigslist Scraper</title> + <style type="text/css"> + #item-list { position: relative; } + .item { margin-bottom: 10px; width: 340px; height: 380px; float: left; margin-left: 10px; } + .item-title { display: block; font-size: 1.3em } + .item-price { font-weight: bold; padding-left: 20px;} + .item img { display: block; } + </style> +</head> +<body> +<h2>Craigslist Scrapper</h2> +<span>get list of current WRX STi parts for sale in Chicago area</span> +<pre> + url: {{ baseurl }} + query: {{ keyword }} + + author: fatalhalt + https://github.com/fatalhalt/CLscrap + +</pre> +<div id="item-list"> +{% for i in data %} + <div class="item"> + <a href="{{ baseurl }}{{ i.link }}" class="item-title">{{ i.title }}</a> + <span class="item-date">{{ i.date }}</span> + <span class="item-price">{{ i.price }}</span> + <span class="item-hood">{{ i.hood }}</span> + <img src="{{ i.img }}" alt="img" /> + </div> +{% endfor %} +</div> +</body> +</html>
\ No newline at end of file diff --git a/myapp/views.py b/myapp/views.py index 6b014ac..600a061 100644 --- a/myapp/views.py +++ b/myapp/views.py @@ -2,11 +2,13 @@ from django.shortcuts import render # Create your views here. from django.http import HttpResponse, JsonResponse +from django.shortcuts import render import cl def app(request): - return HttpResponse("hello, app!") + data, baseurl, keyword = cl.query_craigslist() + return render(request, 'index.html', {'data': data, 'baseurl': baseurl, 'keyword': keyword}) def page(request): diff --git a/requirements.txt b/requirements.txt index d6448fc..df760c2 100644 --- a/requirements.txt +++ b/requirements.txt @@ -1,5 +1,4 @@ beautifulsoup4==4.5.3 bs4==0.0.1 Django==1.10.6 -djangorestframework==3.6.2 requests==2.13.0 diff --git a/screenshot.jpg b/screenshot.jpg Binary files differnew file mode 100644 index 0000000..9f36f13 --- /dev/null +++ b/screenshot.jpg |
{kind=link}